I recently spoke at the August 2024 SydJS meetup, with the title of my talk being Stop Moving Your Latency (and start solving it). Among other things, I addressed the trend of developers moving their apps to the edge in an effort to make them more performant. While this is effective to some extent, the main purpose of the talk was to advocate for the (perhaps less exciting and hype-driven) approach of simply making your website faster.
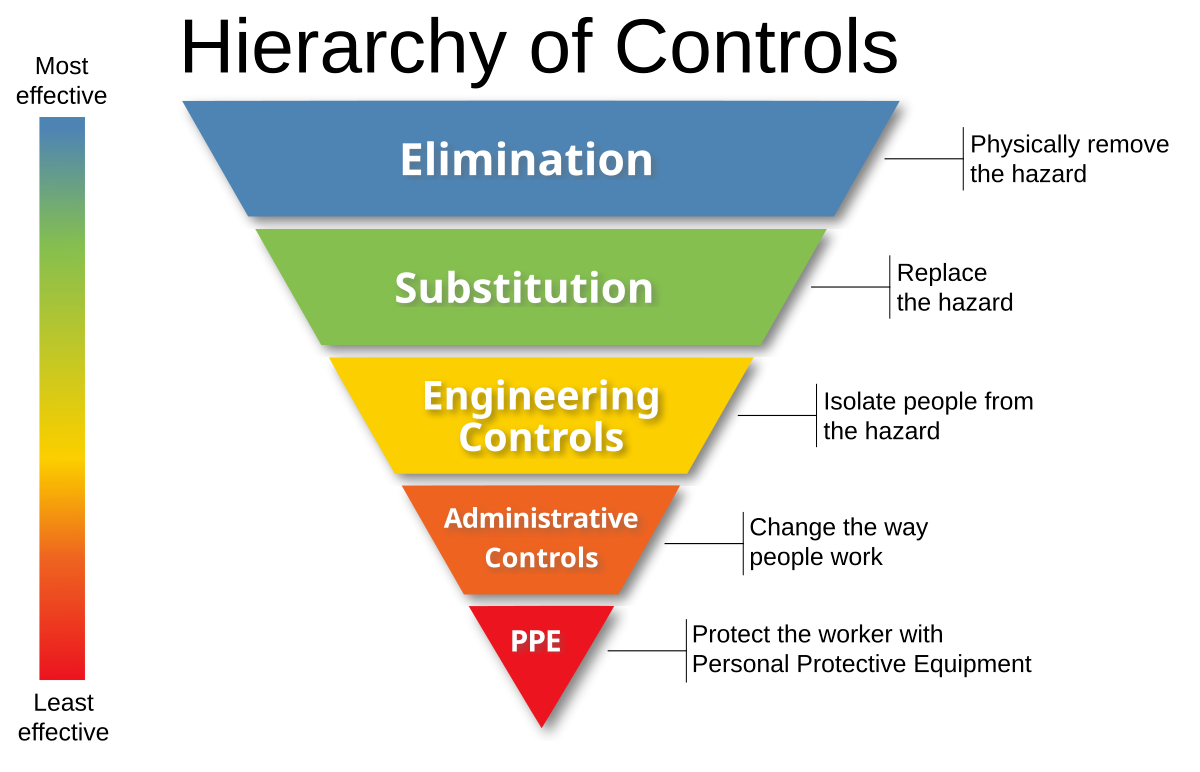
This is going to sound like a stretch at first, but I like to relate optimisation to how workplaces do hazard management. If you’ve ever been blessed with a Workplace Heath and Safety presentation, you’ve probably seen the hierarchy of risk management.
I think this is a really good way to look at managing latency. Like workplace hazards, latency is unavoidable. So we can implement this hierarchy with a few subtle changes.
- Eliminate the Risk → Eliminate the Latency
- Substitute the Risk → Substitute the Latency
- Engineering Controls → Isolate the Latency
- Admin Controls → Move the Latency
- PPE → Loading and Skeleton States
The first, and most effective step is always to eliminate your latency. No matter what scale you’re at, making a database query twice as fast has a tangible benefit.
Second, you can substitute the latency. Use that time more efficiently, see what you can do while you’re waiting for your database respond. And look at the overhead of those queries – what slows them down beyond the query itself.
Next, isolate the latency. This is pretty well a solved problem – we’re talking caching, background workers, etc. Do the slow stuff when the user isn’t staring at a loading spinner.
You’ll notice that moving the latency – that is, geographically moving it – is all the way down the bottom. Everything above this point is more efficient than putting your app everywhere. A slow app that runs near the user is still slow, it’s probably just more expensive to run now.
And finally, our last ditch effort, skeleton states. I’ll say it again and again – they’re objectively an awful user experience. We have the tech to minimise them on good internet connections.
Eliminate the Latency
Let’s go through a few quick strategies for each of these. Starting with eliminating latency, CTEs are amazing. If you don’t know what these are and you work at all with relational databases, go home and research them. Once you’ve got them figured out, they let you do an impressive amount of compute directly on the database, avoiding round trips to your server. The Drizzle ORM supports them out of the box, and you can use raw SQL if you want to use them in Prisma. As well as that, Indexes are incredibly easy to add and give you such an immense benefit, which we’ll come back to in a minute.
It should go without saying, but there’s a lot to be said for actually understanding the computational cost of the operations your code is performing. JavaScript does a really excellent job of hiding this away, which is great in a sandboxed browser context, but in Node or any flavour of serverless the cost of a memory leak or some unexpected recursion is a lot higher and further reaching (and a lot more expensive).
Finally, a big one for me is not letting your ORM become a black box. Every ORM has the ability to spit out the SQL it generates in one way or another, so be critical of what it generates, and don’t hesitate to get your hands dirty and rewrite them by hand. I’ve seen up to 7x performance improvements in some apps just by doing this.
Substitute the Latency
A pretty obvious one to anyone familar with databases, connection pooling should be a no-brainer. If you don’t know what it is you either don’t need it or you’re using it without realising. Prisma has connection pooling enabled by default, and Drizzle makes it easy to use for drivers that support it.
Parallelisation is both hard to say and hard to implement. As a rule, if you have queries that don’t depend on each other they should be either combined into one query (CTEs are your friend there) or parallelised. If they are dependent, try and use a transaction or a single query, but that falls more under eliminating latency.
Lastly, if your platform allows, there comes a point where upgrading your compute power is something that just needs to happen.
Isolate the Latency
My first strategy is here is background workers. They’re fantastic, especially when you’re operating at a large enough scale to be able to run them on a separate machine. Of course serverless and edge are a different beast altogether, but there are options there too. That said, the fact that these things are so difficult on serverless compared to traditional hosting should be a deterrent to jumping on the edge compute hype train.
Caching also falls under isolating latency, because you’re isolating the latency of a database query to a single request then caching the response so that future requests don’t encounter the same latency. Caching is interesting to me because the majority of apps out there have good but not great caching. But this makes sense. I would characterise great caching as proper caching of regularly accessed data in a way that keeps data as fresh as possible – consistently clearing or updating the cache when writes are made and having medium-to-long TTLs. Good (and that’s a loose term) caching, on the other hand, pretty much just lowers the TTL on cache entries as a means of keeping the cache fresh-ish. So at the expense of some data freshness, we’ve been able to ignore all our problems with invalidation and the like.
This approach doesn’t scale, though, because the amount of stale data you’re serving and the impact of that is entirely dependent on your request rate. Cache TTLs are duration-based - a cache entry doesn’t expire after it’s been served n times. And if you’re not clearing your cache properly on database writes, the result of serving stale data can be a pretty awful UX.
I should mention that it’s also perfectly valid to apply multiple and different kinds of optimisation strategies to different latency sources or queries. But by starting at the top of this hierarchy and working your way down, you set yourself up for the best results and scalability.
Just quickly, pagination also falls under isolating the latency, and should be a no-brainer for any new app and most existing ones. The benefit you can get from just adding a LIMIT clause to your database query is incredible, especially when you’re doing crazy joins.
Move the Latency
And on that note, we get to silicon valley’s favourite strategy. It’s very difficult to sell optimising your SQL queries (although perhaps not with AI being the thing that it is now), but edge computing? That’s an easy sell. The problem I have is not with people running apps on the edge, but using it as an excuse to write bad code. By all means, move your compute closer to your users and your data closer to your compute, but if you have an existing application, the effort to optimise your queries has a far greater potential for improvement and be a significantly more efficient use of time and money.
Moving your database closer to your compute is similar - though more nuanced and perhaps harder to sell. Again, this is a totally valid option, but don’t get half-arsed about this stuff. Moving your compute without your data is something that’s all too common. Database replication is notoriously complex, but that, too, is the cost of moving to the edge. There’s no use moving your compute to the edge without moving your data nearby too, that’s only going to make matters worse.
I also consider moving latency across borders from server-side to client-side to be moving the latency. It can still be net good – better that a user sees a skeleton state than a white page – but as far as UX is concerned, a genuine improvement in loading time with the page being complete on load is far more significant.
All that said, these things are pretty trivial choices when you’re creating a new app – with the state of Cloudflare Workers and libraries like tRPC there has never been a better time to start an app that runs on the edge and has some client side fetching and mutations. But for existing app, that economics just doesn’t stack app most of the time.
Skeleton and Loading States
When I spoke to this at SydJS, I showed a slide here covered in loading spinners of different varieties and left it that, but I’ll elaborate here.
A loading spinner or skeleton state is evidence to the user that there’s latency in your app. The numbers don’t lie – millions of people abandon purchases every year because of slow loading. They’ll do that whether there’s a spinner or not. Granted, conversion is probably higher with spinners than with a blank loading state - but that’s not the alternative. The alternative is an app that (on a good internet connection) doesn’t need a spinner. If you must significant latency, have a spinner. But always be on the look out for a way to eliminate that latency, because the spinner is a band-aid solution.
Wrapping Up
The big thing on the React scene at the moment is streaming. This is fantastic example of how isolating and moving latency can really improve UX. While this is great, never forget that by optimising your database query, your overall latency is down, and you still get a better UX. Never forget that you will always create a better experience by optimising at the top of the pyramid, not at the bottom.
Shameless Plug
If the performance of your application keeps you up at night, consider dropping me a line. I love to freelance and help companies get their websites and apps running as fast as possible.